



New course launch: "Computer vision from scratch"
Machine Learning for practical computer vision


About 10 years ago, I worked on an interesting problem statement during my undergraduate at IIT Madras. It was to build a traditional (non-ML) algorithm for detecting rice grain varieties from various types of images. This was my first deep dive into machine vision research.
I used no ML, just pure math and logic applied on the results obtained from traditional image filters for thresholding and edge detection. Our paper got accepted to the highly competitive International Conference for Machine Vision (ICMV) held at Nice, France. [Paper link]
While presenting at ICMV, one thing was very clear to us: the field was swiftly evolving. More and more researchers were abandoning purely rule-based vision techniques and gravitating toward Machine Learning, particularly deep neural networks. This shift signaled a major turning point in computer vision research.
In the decade since, deep learning has radically reshaped computer vision. Techniques that were once considered advanced (like hand-engineered features and classical algorithms) have given way to neural networks capable of learning powerful, generalized representations of images. This move has fueled breakthroughs in areas ranging from self-driving cars and facial recognition to medical imaging and robotics. While working on cellular-image processing at MIT, I had no doubt that I should use Deep Learning models.
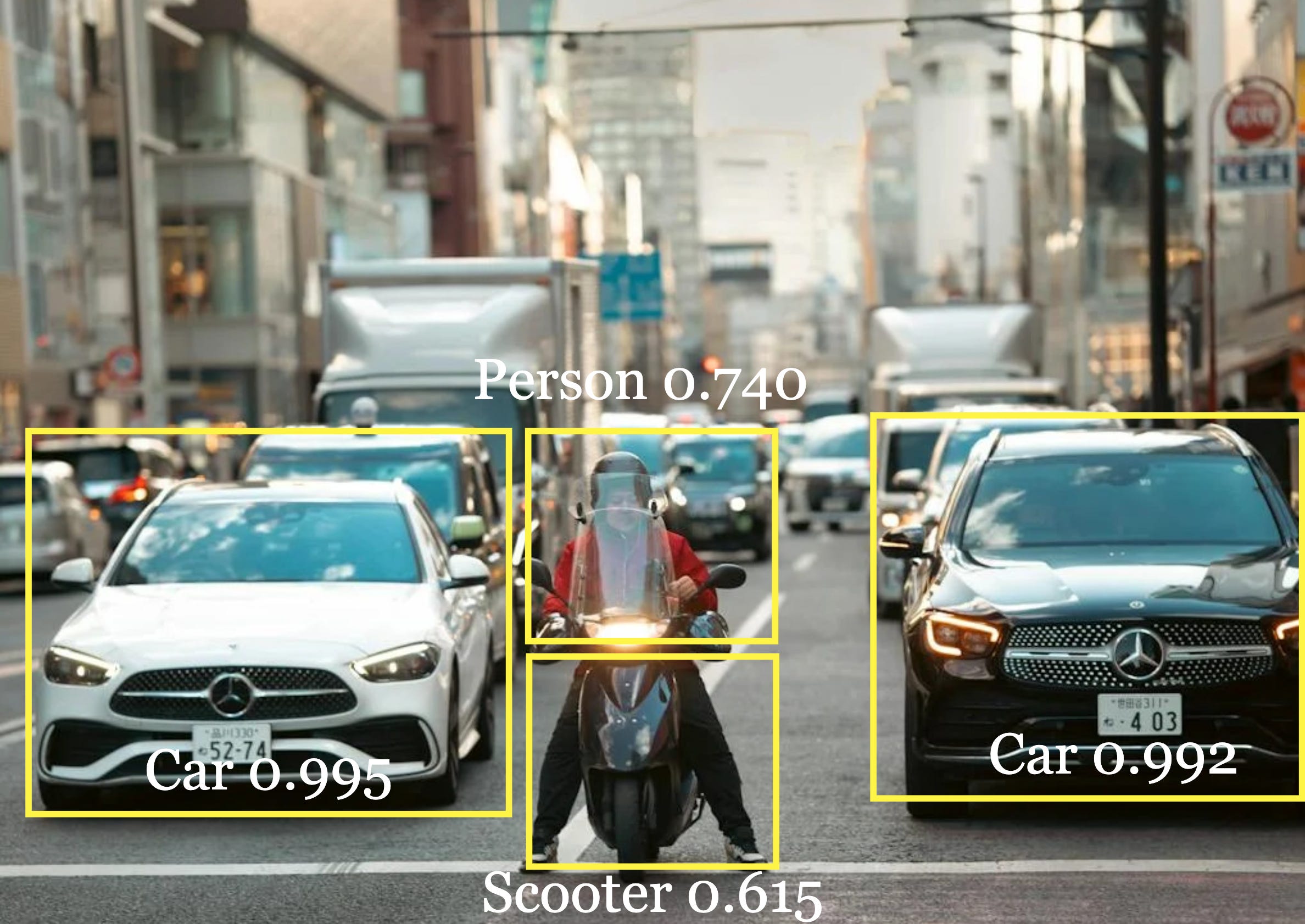
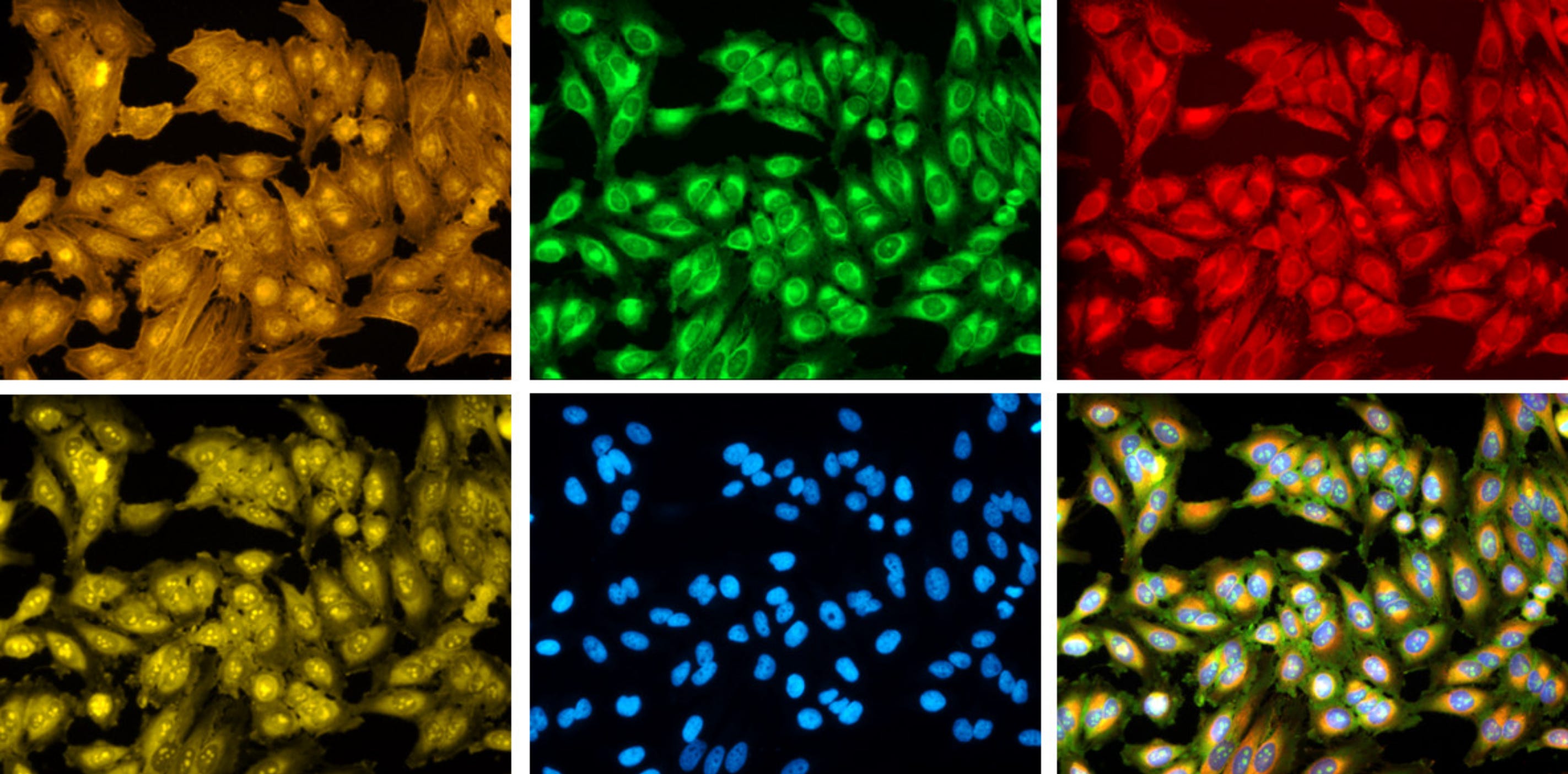
After experiencing the initial wave of deep learning revolution, and watching it transform industries over the past ten years, I realize there is a pressing need for a structured curriculum that covers computer vision including its history, basic foundations, and modern techniques for practical CV applications.
Thus I decided to create a full-blown course titled “Computer Vision from scratch” which I will be releasing for free on Vizuara’s YouTube channel. I will start from the very basics of image processing, covering the foundations of computer vision in the first part of the course. In the second part of the course I will be covering practical aspects of computer vision, for folks who wish to transition their career to computer vision.

Elon Musk has long been an advocate for camera-based vision systems in Tesla vehicles, arguing that they should operate much like humans do. Humans rely on their eyes to perceive depth and motion without external devices, so Musk believes that cars equipped with advanced neural networks and cameras can match or surpass human-level perception. This approach deliberately excludes LIDAR, which Musk has often described as unnecessary for achieving robust autonomy. By teaching the car to interpret visual cues the way we do, Tesla aims to replicate the natural behaviors of human drivers in an autonomous setting.

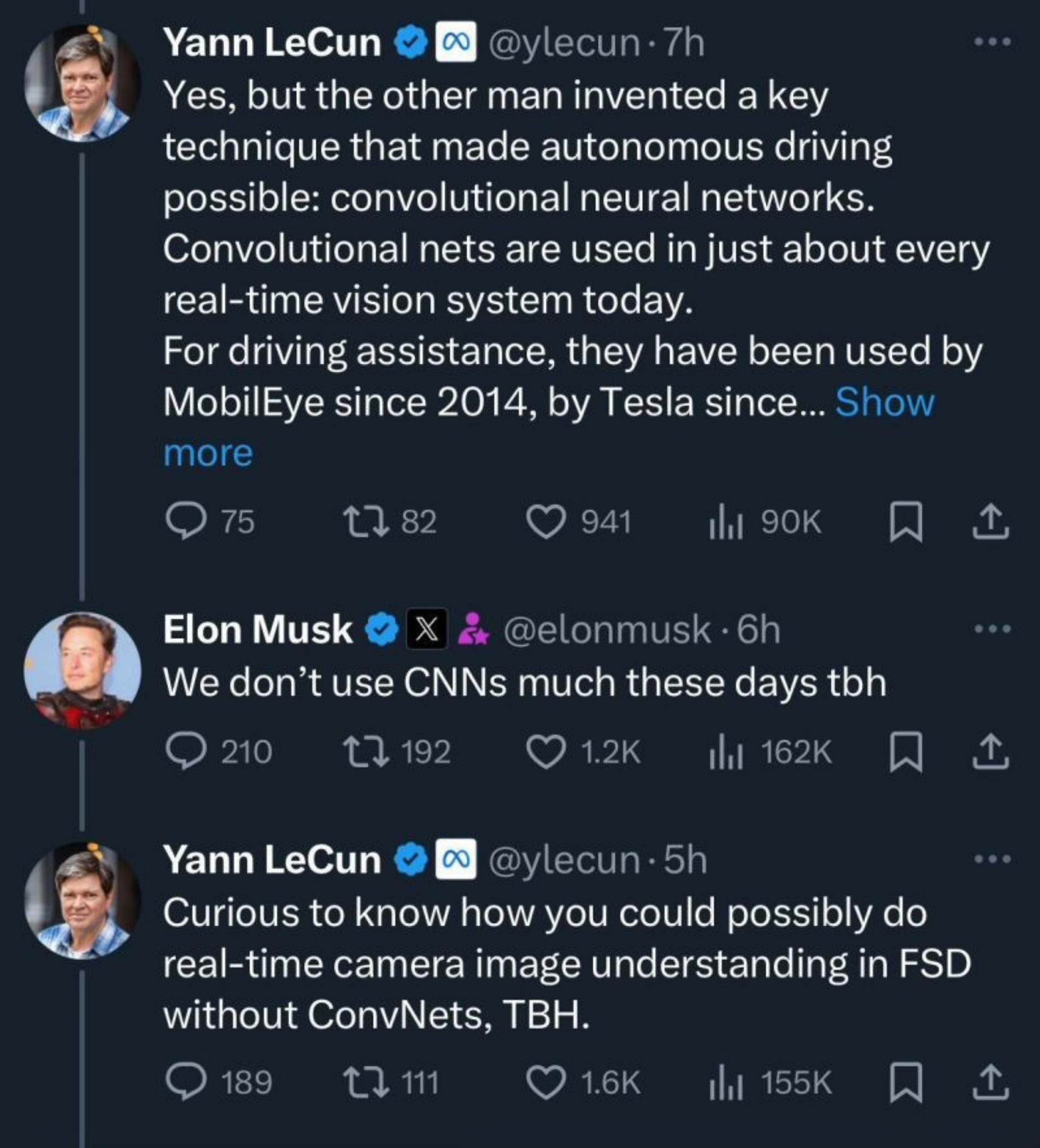
Whether the future Tesla self-driving cars use LIDAR extensively or not, there could not be a better time to take a deep dive into computer vision. Computer vision is transforming industries like healthcare, manufacturing, and retail, enabling breakthroughs in medical diagnostics, quality control, and immersive user experiences. By automating the extraction of insights from visual data, it is revolutionizing everything from autonomous vehicles and robotics to surveillance and consumer applications - making now the ideal moment to harness its potential and shape the future.
So let us start.
Course structure
PART 1: Module 1-6 Computer Vision foundations
Module 1: Machine Learning for computer vision
Lecture 1: Rule-based v/s ML-based approaches
Introduction to computer vision
Evolution from rule-based to ML approaches
Inception of AlexNet
Differences between ML and traditional programming
Deep learning use cases in computer vision
Module 2: Let us build some basic models
Lecture 2: Building a simple linear model (no activation function)
Defining the dataset
Reading images, scaling, and resizing
Using TensorFlow
Building a simple linear model for classification
Lecture 3: Building a simple Neural network (no convolution)
Difference between linear and non-linear models
Hidden layers and activation functions
Gradient descent, back-propagation and optimizers
Hyper-parameter tuning
Defining and training the neural network
Testing the neural network on custom dataset
Lecture 4: Overfitting
What is overfitting?
L1 and L2 penalties, dropout, early stopping
Using a validation dataset for monitoring
Balancing model complexity with dataset size
Module 3: Convolutional Neural Networks
Lecture 5: What is a Convolutional Neural Network?
Convolutional filters and local receptive fields
Parameter sharing for efficient image feature extraction
Historical development of CNN theory
Kernel size, stride, and padding
Max pooling versus average pooling
Lecture 6: Historical CNN architectures
AlexNet breakthrough
Key ideas behind VGG and Inception
Role of competition datasets like ImageNet
Lecture 7: Deeper networks – ResNet and DenseNet
Skip connections and residual blocks
Trade-offs in network depth versus width
Dense connectivity patterns
Efficiency and accuracy trade-offs
Lecture 8: Transfer learning and fine-tuning
Loading pre-trained models for feature extraction
Full fine-tuning versus partial freezing
Learning rate scheduling and differential rates
Module 4: Vision transformer
Lecture 9: Vision transformer theory
Why transformers can replace convolutions in some cases
Attention mechanisms in computer vision
Strengths and weaknesses of transformer-based architectures
Lecture 10: Vision transformer application
Practical steps for training a vision transformer model
Adapting existing transformer libraries and checkpoints
Comparing performance and efficiency to CNN approaches
Module 5: Object detection
Lecture 11: Intro to object detection
Bounding boxes and intersection over union
Classical detection vs deep learning methods
Overview of relevant datasets
Lecture 12: YOLO architecture and training
Real-time detection principles
Anchor boxes and label formats
Scaling yolo for different domains
Lecture 13: RetinaNet and focal loss
Addressing class imbalance in detection
Single-stage detection improvements
Understanding the focal loss function
Module 6: Image segmentation
Lecture 14: Fundamentals of image segmentation
Semantic segmentation vs instance segmentation
Evaluation metrics like MIoI and Dice coefficient
Classical segmentation vs neural approaches
Lecture 15: U-Net and Mask R-CNN
Encoder-decoder design patterns in U-Net
Instance segmentation with Mask R-CNN
Practical applications and labeling challenges
PART 2: Module 7-12 Computer Vision practicals
Module 7: Creating vision datasets
Lecture 16: Dataset collection and labeling
Collecting images from various sources
Manual labeling for classification and detection
Multilabel tasks and bounding box considerations
Crowdsourcing and large-scale labeling services
Lecture 17: Automated labeling and addressing bias
Labels from related data and self-supervised learning
Noisy student approach
Recognizing selection bias and measurement bias
Splitting datasets and minimizing data leakage
Module 8: Data preprocessing
Lecture 18: Data quality and transformations
Image resizing, cropping, and color space conversions
Ensuring consistent aspect ratios
Common pitfalls in data pipelines
Lecture 19: Data augmentation and training-serving consistency
Random flips, rotations, and color distortion
Information dropping (cutout, mixup)
Avoiding training-serving skew
Integrating preprocessing in the model vs external scripts
Module 9: Training pipeline
Lecture 20: Efficient data ingestion
Storing data in tfrecord format
Parallel reads, caching, and sharding
Maximizing gpu utilization
Lecture 21: Distributing training
Data parallelism with gpus
Mirrored and multiworker strategies
Introduction to tpus and their advantages
Lecture 22: Checkpoints and automated workflows
Checkpointing best practices for resilience
Model export using savedmodel and deployment formats
Hyperparameter tuning with serverless pipelines
Module 10: Model quality and continuous evaluation
Lecture 23: Monitoring training and debugging
Using tensorboard for metrics and visualizations
Detecting anomalies in gradients or loss curves
Interpreting weight histograms
Lecture 24: Metrics for classification, detection, and segmentation
Accuracy, precision, recall, and f1 score
ROC, AUC, and confusion matrices
Intersection over union and mean IOU
Lecture 25: Ongoing evaluation, bias, and fairness
Sliced evaluations for subpopulations
Measuring bias in model outcomes
Setting up continuous evaluation in production
Module 11: Model predictions and deployment
Lecture 26: Prediction workflows
Batch prediction using apache beam
Real-time serving with tf serving and rest apis
Handling pre- and post-processing at inference
Lecture 27: Edge deployment
Model compression and quantization strategies
Tensorflow lite for mobile and embedded devices
Overview of federated learning and privacy considerations
Lecture 28: Trends in production ML
Pipelines and orchestration with kubeflow
Explainability methods (grad-cam, saliency maps)
Comparing no-code solutions to custom approaches
Module 12: Advanced vision problems and generative models
Lecture 29: Advanced object measurement and pose estimation
Ratio-based measurement using reference objects
Counting objects via density estimation
Keypoint detection and multi-person setups
Lecture 30: Image retrieval and search
Building image embeddings for similarity search
Large-scale indexing and retrieval methods
Practical considerations for dimensionality reduction
Lecture 31: Autoencoders and Generative Adversarial Networks
Autoencoder architectures for reconstruction and anomaly detection
Introduction to GANs for image-to-image translation
Super-resolution and inpainting applications
Lecture 32: Image captioning and multimodal learning
Image-to-text pipeline fundamentals
Combining CNN and transformer-based language models
Future directions in multimodal AI
Lecture 33: Course summary
Recap of entire course modules
Major concepts and practical takeaways from each module
Common pitfalls and strategies for overcoming them
Recommendations for further learning and advanced reading
How to continue building real-world computer vision applications
Where will the lectures be released?
The lectures will be released on the “Computer Vision from Scratch” playlist on Vizuara’s YouTube channel: Link
Here is the link to the introductory lecture:
This will be really helpful for me. i have seen many courses related to NLP.There are hardly few which focused on CV.
Really thanks for these efforts